The Matching Method
In the first article, we listed some rules for each seed-group and the overall table. More often than not, a particular year will not be defined by any of the rules. If that is case, the first option would be the matching method, where we simply match the year in question to its best comparable year. For demonstrative purposes, we will employ the matching method on 2018 for all four seeds.

Here's what we can see:
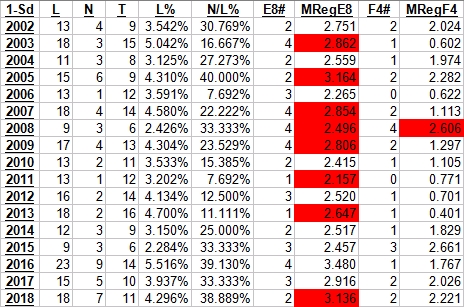
- Three years (2003, 2007, and 2013) produced 18 total losses among 1-seeds. As for predictive value, those three years produced appearance-by-round (ABR) totals of 4-4-4-1, 4-4-4-2, and 4-3-1-1 with win totals of 13, 14, and 9. Of those three years, 2007 is closest to 2018 when looking at all other columns (N, T, L% and N/L%) while holding L-value equal. 2007 accurately predicts 2018's F4-count of 2 while 2013 accurately predicts 2018's WTot of 9. When looking at the other columns (N, T, L%, and N/L%), 2018 deviates so far from these three years, I most likely would have used these three years as contrarian models than predictive models.
- No year produced 7 N-type losses, but the closest two years are 2005 and 2016 with 6 and 9 respectively, with 2005 being slightly more comparable to 2018 than 2016. Neither year's WTot matched 2018's, but 2005 matched the F4-count and the E8-count of 2018.
- Three years (2005, 2009, and 2012) approximately matched the L% values, again with 2005 being the most similar when evaluating the remaining factors.
- Two years (2005 and 2016) matched the N/L% of 2018, and these have already been evaluated in the second bullet. Ironically, the next closest matches would be 2007, 2009 and 2017 with 33% N/L%, and we knew from other predictive models that 2018 would be nothing like those three years.
- Even though we didn't find a year that consistently matches with 2018, the primary takeaway from the matching method for 1-seeds is the predictive power for F4-counts and (to a lesser extent) E8-counts.

Here's what we can see:
- One year (2010) produced 27 total losses among 2-seeds, with three more years (2002, 2017, and 2014) producing approximately close totals of 25, 25, and 28. Of these four, 2018 matches up with 2010 in terms of raw stats (N and T) and matches up with 2017 in terms of relative stats (L% and N/L%). Between 2010 and 2017, 2017 is a dead-ringer for 2018's 2-seeds even though 2010 was a closer match to 2018 for the tournament at-large.
- Three years (2005, 2007, and 2015) produced 5 N-type losses. Of these three years, 2005 is far closer to matching the other values (L, T, L% and N/L%) of 2018 than either 2007 or 2015. Even better, 2005 (like 2017 before) is a dead-ringer for 2018's 2-seeds.
- When looking at the L%, five years (2003, 2005, 2006, 2013, and 2017) come to our attention, as all five are within 0.200 of 2018's L% of 6.444. Even though 2003 almost perfectly matches the 2018 L%, it is also appears to be the furthest away from all other comparative stats. 2013 suffers from the same divergences, so we can safely drop these from our attention. Of the remaining three years, 2017 is the closest of all other comparative stats except for N/L% which belongs to 2006. For predictive purposes, all five years suggests either zero or one 2-seed in the F4 (with three accurately predicting 2018's F4-count of zero), either one or two 2-seeds in the E8 (with three accurately predicting 2018's E8-count of one), and either seven, eight or nine total wins in the tournament (with two accurately predicting 2018's WTot of seven).
- When looking at the N/L%, only one year (2016) matches 2018, with four more years (2006, 2017, 2008 and 2009) being approximately close. Again, 2017 is the closest match of the four years, with 2006 in a close second place.
- The primary takeaway from the matching method for 2-seeds is finding three approximate matches for 2018 in the years 2005, 2006, and 2017, with two of those years perfectly matching the tournament performance of 2018's 2-seeds. I love this kind of accuracy, and if I had played around with this tool and this method last year, I wouldn't have put two 2-seeds in my 2018 challenge bracket.

Here's what we can see:
- Only one year (2013) matches the total losses among 2018 3-seeds with 28, yet three more years (2007, 2011, 2014) have 27 and four more years (2002, 2004, 2009, 2010) have 29.
- Looking at the matching year first, 2013's 3-seeds had one less N-type loss, which possibly indicates stronger 3-seeds, and 2013's 3-seeds had a higher L%, which possibly indicates the rest of the 2013 field was relatively stronger to 2013's 3-seeds than the 2018 field was to 2018's 3-seeds. When comparing the actual results, 2018 had a higher WTot, a higher F4-count, and a higher R64-count than 2013, which should be expected based on the inferences made from the matching method.
- Of the approximately close years, 2007 is the closest match by a long shot, with 2011 edging out 2009 for second place do to its similarity in L%. 2007 produced a 4-3-1-0 ABR model, which is a little off of 2018's 4-2-2-1 ABR model. 2011 produced a 4-2-1-1 model, which only deviates from 2018 in the E8-count.
- Three years (2004, 2012, and 2017) match 2018's N-type total of 7. Though none of these are perfect matches, 2004 is the closest to all other comparable stats except for L%, and 2017 is the closest to that value. Both of those years produced a 4-3-1-1 model, which is slightly off of 2018's 4-2-2-1 model, so if we make some educated inferences like we did in the previous bullet point, maybe we stumble upon the correct model.
- Five years (2005, 2006, 2007, 2008, and 2011) approximately match the L% of 2018, as all five are within 0.200% of 2018's value of 6.683%. We already know about 2007 and 2011 from the work above, so let's look at the remaining three. Of these three, 2008 edges out 2005 for the closest, with 2006 being too far apart to be considered. 2008 had three fewer total losses but a slightly higher L% than 2018, which could mean 2008's 3-seeds are relatively weaker to the 2008 field than 2018's 3-seeds to the 2018 field. This does explain why 2008 saw fewer 3-seeds in the F4 than 2018, but 2008's 3-seeds had one more tournament win than 2018's did.
- Three years (2004, 2005, 2008) produce an N/L% within 1.1% of 2018, with three more years (2007, 2012, and 2009) within 2.8% of 2018. Also, 2013 is only 3.6% away from 2018. Ironically, all seven of these years have been discussed above, with their differences noted.
- Like the 1-seeds, 2018 doesn't have a clearly comparable year, but if some inferences are applied to a collective of the years discussed (2013, 2007, 2004, 2011 and 2008), a predictive composite could be to model 2018.

Here's what we can see:
- Two years (2003 and 2014) match the total losses of 2018 with 25, and another year (2009) is approximately close with 26. Of these three years, 2003 is the closest is all measures except L%, which has a difference of more than 1%. While 2003 produced the same WTot and 2018, the ABR model 3-0-0-0 was slightly different than 2018's model of 2-1-0-0.
- One year (2016) matched 2018's N-type loss total of eleven, and three more years (2003, 2006, and 2010) are approximately close with 10, 10, and 12 N-type losses. All four years managed to see one 4-seed lose in the R64, which could be explained by the double-digit quantity of N-type losses (this is assuming 2007 could be an outlier year).
- One year (2005) approximately matched 2018's L%. 2005 had fewer total losses, fewer N-type losses, slightly higher T-type losses, and a significantly lower N/L%. This could definitely mean 2005's 4-seeds were overall better than 2018's 4-seeds, which would explain why 2005's ABR model (3-1-1-1) is better than 2018's model (2-1-0-0) at all rounds except the S16.
- Only three years (2003, 2007, and 2010) are approximately close to 2018's N/L% of 44.000%, which was the highest on record. If roughly four out of every ten losses incurred by a 4-seed is coming at the hands of a team not qualified to be in the tournament, it screams very loudly that the 4-seeds in that year are vulnerable. Of these three years, two years saw one 4-seed defeated by a 13-seed, two years saw only one 4-seed make the S16, and all three years saw none remaining in the E8 or F4. Ironically, 2003 is here again as the closest match with 2010 being the next closest comparison. Their ABR models of 3-0-0-0 for 2003 and 3-1-0-0 for 2010 would make a great composite for 2018's ABR model of 2-1-0-0.
- With the matching method, we find a really good comparison to 2018's 4-seeds in 2003. With some inferential tinkering, it's possible that we could have predicted 2018's ABR model. Strangely enough, 2008 produced the exact same ABR model as 2018, but it had absolutely no statistical comparison to 2018, which is a shame.
The Regression Method
One of the best explanatory tools in statistics is regression modeling. To be honest, I wasn't convinced regression analysis would be feasible because very few of the data points being used are statistically independent. The raw statistical categories (L, N & T) have a definable relationship to one another: L = N + T. Likewise, the relative statistical categories (L% and N/L%) use the same raw stat L in their calculations. Even the WTot stat demonstrates functional dependence on the win-by-round stats. You can see this functional dependence really clear by looking at the 1-seed chart above. In 2018, the NCAA tournament saw its first 16-seed defeat a 1-seed. As a result, the subsequent rounds (S16, E8, and F4) can never have more than three in the cell. Even if the remaining three 1-seeds had reached the F4, the maximum value of 2018's WTot would have been 12 (or 3+3+3+3). Thus, each round round has a functional dependence on the preceding round, and the WTot has a functional dependence on all four rounds. With the lack of statistical independence, I was hesitant to even apply multiple regression, but since this is experimentation, it was worth a look. After a lot of trial and error, the only regression models that had any level of suitable predictability used L% and N/L% as input variables and F4 and E8 appearance counts as output variables. The only assumption being made is the output variable is within the range of
two potential outcomes. In simple terms, round the output variable both
up and down to predict the potential outcome. For example, if the output variable for the 1-seed F4 model is
2.3, then it is predicting either two or three appearances by 1-seeds in the F4. With that said, all of the results are below, and as usual, I'll start with the 1-seeds.

Here are the details:

Here are the details:

Here are the details:

Here are the details:
I hope this (three-part, lol) two-part foray into the seed-group loss table was exciting and educational. As you can tell, it needs a lot of work in order to make it a reliable predictive tool. In its current state, the rule-based pattern analysis and the matching method provide foundational applications with the regression method providing only supplemental applications. Some future improvements/extensions to this tool would be the inclusion of win data (in the same fashion as the loss data) for comparative purposes and a seed-curve model like the one envisioned in the Darwin Rule from the first article. The big question: Would I make predictions for the 2019 tournament based on its results? It is very unlikely since this tool is in its infancy, but I will have a look at what it produces. Considering the 1-seed F4 regression model called for one or two 1-seeds to reach the 2018 F4 and yours truly erroneously called for zero, I'd be fool not to look at it. Until next time, thanks for reading my work and I hope you return in two weeks for the March Edition of the Quality Curve Analysis.
Here are the details:
- Regression Equation for F4: -38.42098*L% + 5.99359*N/L% + 1.54042
- Regression Equation for E8: 27.7817*L% + 2.16481*N/L% + 1.10055
- Plain and simple, the E8 regression model dumps on itself (more in the thoughts section).
- The F4 regression model fails to predict the 2008 F4, which also happens to be the only year in which all four 1-seeds reached the F4. This predicted value is the second largest of the group, coming up 0.055 short of 2015's predicted value, which produced three 1-seeds in the F4.
- The difference in sign of the L%-coefficient for the two models is the most interesting part.
- The F4 model has a y-intercept of 1.54, but somehow it still has to account for the possibility of zero 1-seeds in the F4 (2006 and 2011). This means one of the indicators is going to have a negative relationship with F4 appearance counts in order to produce a predictive variable below 1.000. This may explain why this model fails to predict the possibility of four 1-seeds in the F4 like 2007.
- The E8 model flips to positive for both coefficients, including a y-intercept above 1.000. This model simply assumes there is no way a tournament can produce a zero count in the E8 appearances for 1-seeds. This change in sign of the L%-coefficient may be a good reason why the regression method fails to consistently predict 1-seed E8 appearances, with eight failures out of seventeen predictions, and the only model to fail this badly.

Here are the details:
- Regression Equation for F4: -15.04405*L% - 2.93472*N/L% + 2.38485
- Regression Equation for E8: -15.56836*L% + 3.72378*N/L% + 1.88958
- The 2-seed F4 model fails to predict 2007, one of four years in which two 2-seeds make the F4. Strangely, the 2007 and 2012 predicted variables are the only ones to not conform with their counterparts. All zero-count appearances are over-estimations (the predicted value is greater than the actual value), all one-count and two-count appearances (except for 2007 and 2012) are under-estimations (the predicted value is less than the actual value).
- The 2-seed E8 model fails to predict 2003. It is the only model failure (excluding the 1-seed E8 model) that is an over-prediction. Even stranger, the L% for 2003 is .001 within that of 2018, and 2018's predicted variable is within its actual range. I would think the regression equation could be slightly tweaked to improve its accuracy, but I didn't experiment any since regression calculations attempt to minimize deviations from the line-of-best-fit.
- For these two models, the change in the sign of a coefficient happens to the N/L%-coefficient.
- The F4 model has a y-intercept of 2.38, which implies a starting point of two or three 2-seeds in the F4. This has happened only four times, and all four have been two-count appearances, and the remaining counts have been zero or one. For the model to be predictive, the two input variables (L% and N/L%) must account for the possibility of a zero 2-seeds in the F4. It explains why both factors need negative-value coefficients.
- The E8 model has a y-intercept of 1.89, which means one or two 2-seeds in the E8. This starting point accurately predicts all but two actual E8-counts, with the other two being three-count appearances. The change in sign of the N/L%-coefficient may be indicating N/L% as a contrarian predictor of E8 appearances (higher = more appearances).

Here are the details:
- Regression Equation for F4: -46.43298*L% + 0.86033*N/L% + 3.55821
- Regression Equation for E8: -39.88898*L% - 3.61449*N/L% + 4.96503
- The 3-seed F4 model fails to predict 2004, and oddly enough, it is the only time the model produces a negative output value. What a blessing that would be if the model predicts a negative value and it is right because we know there can't be a negative number of 3-seeds in the F4. The predicted value would have to be zero 4-seeds. Also, the only time the model produces an output variable greater than one is the only time two 3-seeds reach the F4.
- The 3-seed E8 model accurately predicts the range of the actual count on every occasion. Unfortunately, the model has plenty of under-estimations or over-estimations making it very difficult to precisely predict the actual result.
- For these two models, the change in the sign of the coefficient also happens to the N/L%-coefficient, except this time, it changes from positive to negative. I won't go into much detail on this phenomenon, but I will note that these two models have the largest magnitude (absolute value in mathematical terms) for L%-coefficients and y-intercepts than the other three models for both the F4 and E8. I would interpret this to mean the 3-seed data has large variances in explanatory power (and thus, less useful in a predictive capacity).

Here are the details:
- Regression Equation for F4: -19.79386*L% - 2.77253*N/L% + 2.72078
- Regression Equation for E8: -23.54201*L% - 5.33647*N/L% + 3.99575
- The 4-seed F4 model fails to accurately predict the actual range in 2013, which happens to be the only year in which two 4-seeds reached the F4. Most likely, this can be attributed to the outlier phenomenon. Since zero 4-seeds is the most common (12 out of 17 actual outcomes) and one 4-seed is the second-most common (4 out of the remaining 5 actual outcomes), the regression calculation, while minimizing deviation from the line-of-best-fit, cannot offset 2013's deviation without greatly expanding the deviation of the other sixteen years. Thus, the model is left with an outlier (more on this in the thoughts section).
- The 4-seed E8 model also accurately predicts the ranges of the actual outcomes, but it too suffers from the occurrence of over-estimations and under-estimations. It does, however, produce two negative output variables, which means zero 4-seeds in the E8 since a negative count for appearances is impossible. It also makes the 4-seed E8 model complementary to the 4-seed F4 model since zero 4-seeds in the E8 implies zero 4-seeds in the F4. This is very helpful in 2010 when the predicted output variable's range is zero or one.
- This is the only model in which the signs of the coefficients do not change. Since both y-intercepts are somewhat large (two or three in the F4 and three or four in the E8), it is no surprise that both coefficients for L% and N/L% must be negative. No F4 or E8 has had more than two 4-seed appearances, so these input variables must correct the y-intercepts downward for these models to have any chance at being accurate.
- I tried regression analysis on all four groups of seeds for the S16, and it looked like the 1-seed E8 model. I tried it also on the 3- and 4-seed group for the R32, and it was pretty much the same thing. I think #3 explains why this happens.
- The high values of y-intercepts in all of these models and the models having to scale them down with negative-value coefficients is very troubling to me. It makes me question the validity of this method, and I did this from the beginning since I already knew the input variables were not independent.
- For the two times I mentioned "discussed later in the thoughts section," here is what I wanted to discuss. I think these models are heavily swayed by seed-group expectations. For example, 1-seeds are expected to make the F4, 2-seeds to the E8, 3- and 4-seeds to the S16. Thus, if the relative statistical categories accurately reflect the quality of the seed-group, then they should predict the relative performance of the seed-group against seed-group expectations. Since 1-seeds are expected to reach the F4, the 1-seed E8 model will dump on itself because this round is short of seed-group expectations. Likewise, 4-seeds rarely make the F4, so the 4-seed F4 model will predict central tendency toward zero (and occasionally one) appearances. As a result of this influence, the regression method may only work best for each seed-group in accordance with their seed-group expectations (i.e. - 1-seed F4 model, 3-seed and 4-seed E8 model).
Conclusion
I hope this (
No comments:
Post a Comment